 Cloudflare D1
Cloudflare D1 Deno KV
Deno KV DynamoDB
DynamoDB EdgeDB
EdgeDB FaunaDB
FaunaDB Firebase Firestore
Firebase Firestore MongoDB Atlas
MongoDB Atlas PlanetScale
PlanetScale Prisma Postgres
Prisma Postgres Supabase
Supabase Turso
Turso Upstash Redis
Upstash RedisUpdated on 1/21/2025
What is Xata: A Review of Serverless Database Features
 AH
AHAren Hovsepyan
Feature |  Xata.io Xata.io | |
|---|---|---|
Infrastructure, Underlying technology Cloud Infrastructure, database system and underlying egine | PostgreSQL, Apache Kafka, ElasticSearch | |
Serverless Support Serverless and Edge computing support | ||
API | TypeScript SDK | |
Edge Functions Serverless functions that run closer to the user, reducing latency and improving performance. | Edge Caching, support for Edge environments | |
Developer Experience | ||
Database type | OLTP, OLAP | |
Data model Databases store data in models, such as Relational, Columnar or Document based | Relational | |
CLI Command Line Interface tools that allow developers to perform tasks and manage the tool via the command line. | @xata/cli | |
Languages, APIs The languages supporting the database and API interface for inter-process communication | JavaScript, TypeScript SDK, Python SDK, REST API | |
Query language Supported query language such as SQL, MQL, PartiQL, | JSON, MongoDB like query language (MQL) | |
ACID compliant ACID is a set of properties of database transactions intended to guarantee data validity despite errors, power failures, and other mishaps | ||
Self-hosting Support for self-hosted Database instance | Doesn't have support | |
Backups | Requires custom solution via REST API | |
Security & Compliance Offerings | ||
SOC2 Service Organization Control 2 compliance for managing customer data. | N/A | |
Multi-factor authentication Support of the cloud-hosted database for multi-factor authentication | N/A | |
Encryption Cryptographic security at rest and on transportation level | TLS | |
SSO | N/A | |
Monitoring and analytics | ||
Log retention Query log retention usually keeps lofs of operations for debugging and replication purposes | N/A | |
Statistics Tools and APIs for analysing and monitoring of Database performance | N/A | |
Scalability | ||
Replication and Partitioning | Region Groups, group replication, PostgreSQL logical replication | |
What is Xata.io?
Xata.io is a cloud-based serverless database platform that combines the power of PostgreSQL and ElasticSearch. With Xata.io, developers can easily create applications with built-in search functionality and a neat interface for data analysis. Say goodbye to the hassle of managing multiple data stores - Xata.io offers a simple abstraction layer that streamlines both development and operations.
Xata.io key features
Xata is the ultimate solution for Jamstack developers looking to quickly set up their database schema and streamline their development workflow. With Xata, you can enjoy the following key features:
- JSON-Like Schema Definition. Define your data models with ease using Xata's JSON-like schema definition, just like Sanity CMS. Under the hood, Xata will adjust the schema for PostgreSQL and ElasticSearch.
- Relational Data Model. Xata utilizes a relational data model with a defined schema, enabling support for JSON-like objects. It organizes records into tables within databases and offers a range of column types. Relations between tables can be established using link columns, similar to foreign keys.
- Xata is a branchable database, allowing you to properly set up dev environments and replicate data for experiments and feature development with ease.
- Cloud-Based Scalability. Enjoy automatic resource scaling based on usage and performance metrics, thanks to Xata's cloud-based nature.
- Rich Data-Related Functionality. Take advantage of advanced features such as free-text search and aggregations, for a truly rich data experience.
What makes Xata.io different?
A website search feature is crucial for providing a great user experience. With Jamstack, you can create high-performance websites, but to truly maximize its benefits, you need an effective website search feature.
Developers face many challenges when creating website search features. Leveraging multiple tools is necessary to ensure excellent user experience, but this comes at the cost of increased overhead and effort. Setting up separate tools such as Algolia or database systems like MongoDB, PostgreSQL, or MySQL is time-consuming and complex. Traditional CMS tools lack robust analytical and search engine capabilities.
In contrast to other solutions, Xata.io offers a solution that combines all the benefits you need. You can easily set up an effective website search feature and access data with just a few clicks, cutting back on additional effort and time.
Let’s dive deep into Xata.io
With just a few simple steps, let's create a compact database of Medium articles on Xata and develop an API using Vercel Edge Functions to search through these articles. This will showcase how quickly and efficiently you can harness the power of Xata.io to optimize your blog and gain access to your articles in mere minutes.
1. Autogenerate schema based on CSV file
Let’s prepare a database of Medium articles from the following Kaggle dataset. In order to easily import data from a CSV file to the Xata.io database, you need to simply install the CLI tool and run the following command:
npm install -g @xata.io/cli@latest
After successful installation, you need to log in via CLI in order to connect to your Xata.io database on further steps:
xata auth login
Next, you need to run the following command in the folder of your CSV file as follows:
xata import csv file.csv --create --table my_first_table
Remember to replace my_first_table with your table name.
Finally, you can see that our database is populated with the data of CSV files. Moreover, we see that Xata automatically generated a schema for our table.
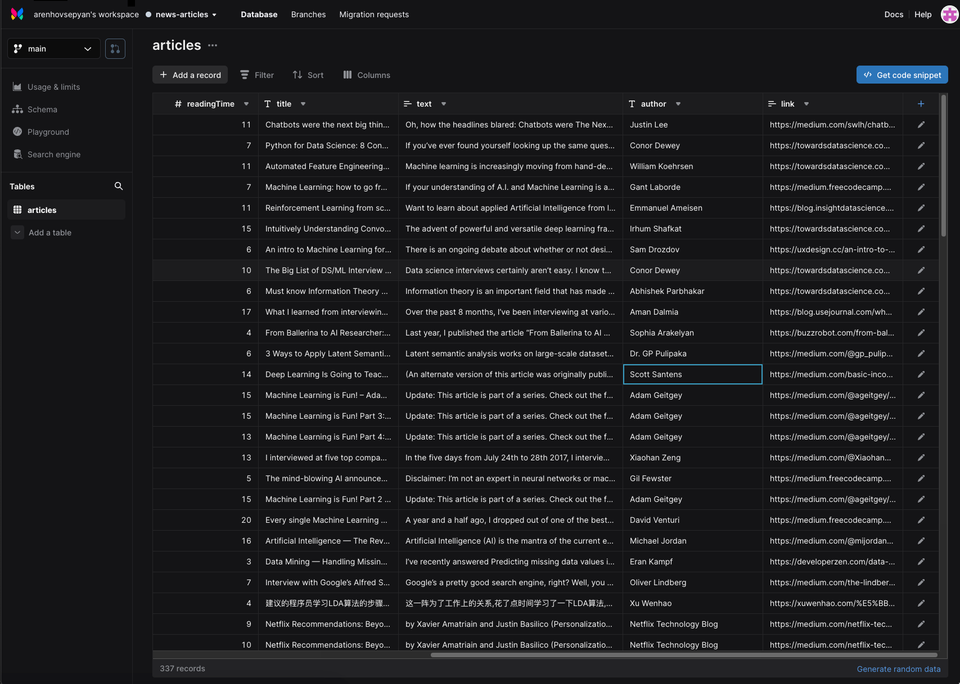
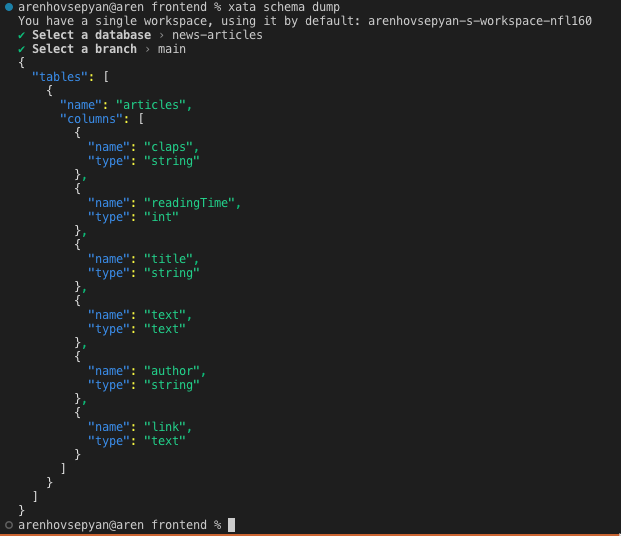
In order to check the autogenerated schema we can run the following command: xata schema dump, which shows us the JSON definition of our schema as follows.
2. Initialize our Xata.io application and set up Xata SDK and configs
Now, since we successfully imported our articles via CLI, we can proceed and create our search API endpoint in Vercel Edge to access our articles via the web.
We will skip the part of scaffolding the Next.js application and Edge Function. You can follow up on this guide.
In order to make requests to our Xata table we need to install the SDK and set up Xata environment variables.
Surprisingly this is super easy to do with a single terminal command in our root folder as follows:
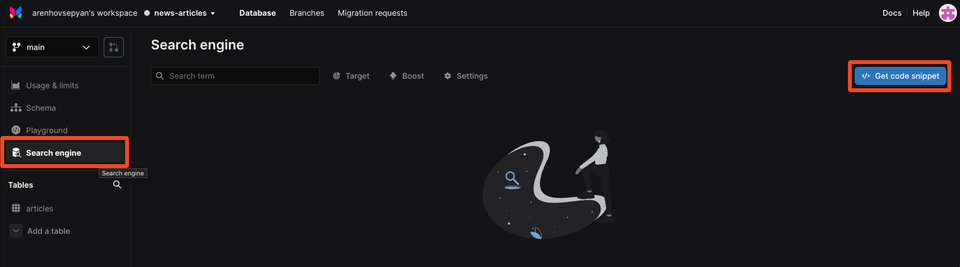
xata init --db https://arenhovsepyan-s-workspace-nfl160.us-east-1.xata.sh/db/news-articlesYou can find this command under the Search Engine section in the Xata dashboard.
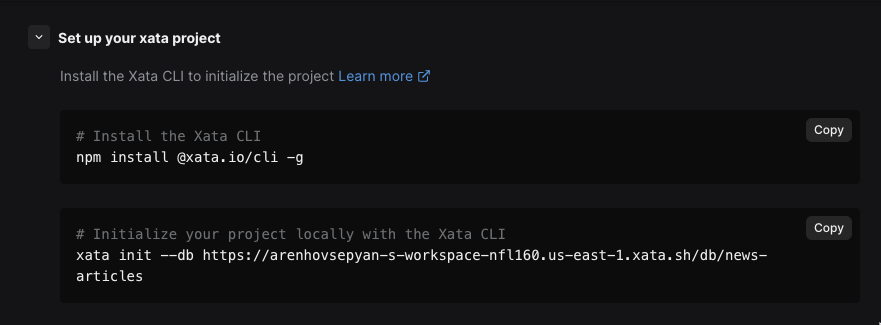
he above command generates the following files, which we will cover shortly:
- src/xata.ts
- .xatarc
- .envsrc/xata.tsgenerates TypeScript types and interfaces for our table schema. Find more here..xatarccontains information on our database’s HTTP interface URL and path to codegen as follows:{ "databaseURL": "...", "codegen": { "output": "src/xata.ts" } }.envcontainsXATA_API_KEYandXATA_FALLBACK_BRANCH. you can find more information about API keys here.
3. Create an endpoint to search our articles
Since we already set up our Xata SDK, we can proceed and finalize our blog search API.
Here is the full code that we need to put under /pages/api/search.ts for our /api/search endpoint In Next.js app with the following content.
import type { NextRequest } from "next/server";
import { getXataClient } from "@/xata";
const xata = getXataClient();
export const config = {
runtime: "edge",
};
export default async function handler(req: NextRequest) {
const query = req.nextUrl.searchParams.get("exp") || '';
const records = await xata.search.all(query, {
tables: [
{
table: "articles",
target: [
{ column: "text", weight: 4 },
{ column: "title", weight: 3 },
{ column: "author", weight: 2 },
],
},
],
fuzziness: 2,
prefix: "phrase",
});
return new Response(JSON.stringify(records, null, 2), {
status: 200,
headers: {
"content-type": "application/json",
},
});
}In the above code, we are using exp query search param as an expression and passing it to xata.search.all method that takes two parameters
- query expression to search
- configuration for our search request
In the configuration object, we can specify the following properties:
tables- is a list of tables that need to be included in the search.- each table contains
targetproperty, where we can specify the boost factor for precise scoring of our search results and ordering by priority and frequency of a given search expression. e.g. in our case, we specify thattextfield is more important thantitleandauthorbyweightproperty. - We can specify the
fuzzinesslevel of our search. By default, Xata searches tolerate typos of one character. You can control this behavior by setting thefuzzinessparameter, which represents the maximum Levenshtein distance for the search terms.
4. Testing our Xata table search
Let’s take a look at what we’ve built together with the help of Xata.io. You can run npm run dev, and our Next.js application should listen under localhost:3000
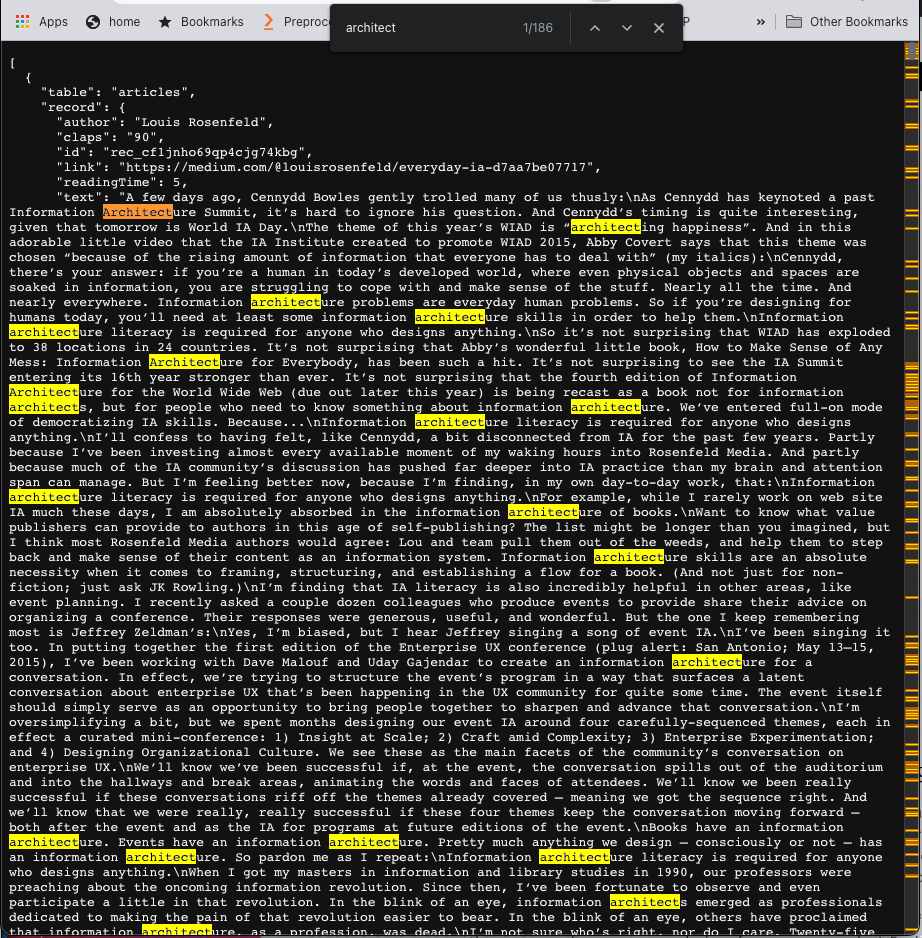
Let’s search all articles that contain the term architect, and we see JSON responses of articles that contain the word architect.
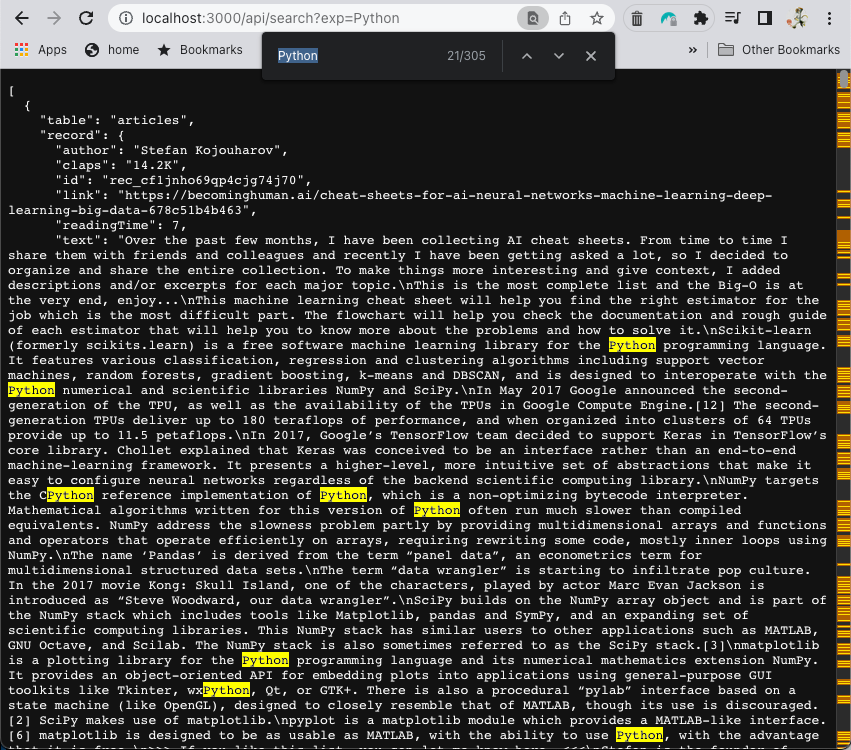
Now let’s search for Python articles. For this, we need to make a request to the following URL:
Final Thoughts
We can see how quickly we can set up our CMS with the help of Xata.io. It has a neat JavaScript SDK that allows us to quickly prototype our application and forget about the overhead of software maintenance of our database and search engine.
By default, it handles search indexing and provides great tools to cover our JamStack website's needs for user search. Simply with multiple lines of code, we utilized a fully-fledged online search for our mini-blog.
Xata is a must-have tool for JamStack developers looking for a fast and easy way to set up their database schema and search engine. It offers a JSON-like schema definition, a relational data model with a strict schema, support for JSON-like objects, and various column types.