May 20, 2025
15 min
AI For Everyone: How Open Source Models Are Changing The Game
Joas Pambou
Introduction
AI is having a big impact, and it's getting even bigger and faster. Stuff that seemed really cool just six months ago now appear outdated as new breakthroughs are coming out constantly. This progress isn't limited to natural language models; it also includes computer vision, audio processing, healthcare, software engineering, and more. But, these cool new things are usually only available to a small group of people who can afford to buy them or pay high fees to use them.
Take GPT-4 for example, developed by OpenAI, it’s a powerful multimodal model accepting text, code, images - you name it. It can summarize complex inputs like financial reports, textbooks, even screenshots into concise insights. With capabilities like these, you could build innovative apps like an image enhancer or virtual financial advisor; the possibilities are endless. But here's the thing - OpenAI’s GPT-4 is only available to paying ChatGPT Plus subscribers, with capped usage, and for developers looking to access the API, pricing considerations come into play.
This is precisely why open source AI models are important - it provides free access to cutting-edge capabilities for everyone. Open models enable transparency and customization that closed, proprietary systems lack.
Many leading AI tools like Midjourney or ChatGPT remain closed source, but an open ecosystem is growing. This accessibility is democratizing AI capabilities.
Now let's explore the world of open source models and how they're transforming who can participate in AI innovation.
Democratization of AI through Open Source Models
Democratization means making technology accessible to everyone, not just a select few. Open source does this by freely sharing code online, allowing developers to collaborate, train models for specific use cases, and tweak them as needed.
In this chapter, we'll explore how open source AI makes accessibility and collaboration possible.
Improving Accessibility For Developers
Open-source foundational AI models are making it easier for developers worldwide to access cutting-edge technology. One platform that advocates for the open-source community is Hugging Face.
Hugging Face is the go-to platform for developers seeking to work with large language and vision models. With its transformers' library, Hugging Face makes it easy to work with open-source AI models, meaning developers and engineers like you and me can use powerful large or small language, vision, and multimodal models for our projects without any hassle.
The platform also provides clear tutorials and code snippets to help you integrate these models into your work. Whether you're a beginner or an expert, Hugging Face ensures that using AI models is straightforward in TensorFlow, PyTorch, or any other framework.
Moreover, Hugging Face provides a leaderboard for open-source models, simplifying the selection of the best model for your next AI project.
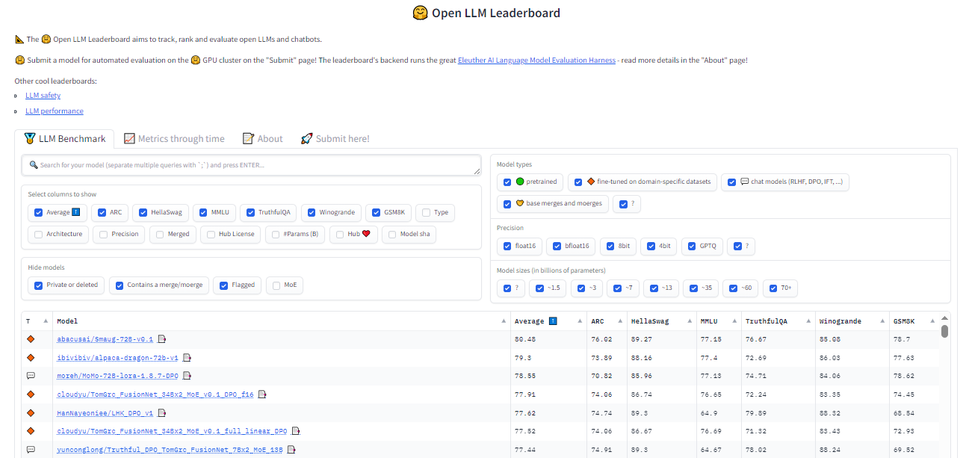
For instance, take a look at Smaug-72B-v0.1, a powerful LLM developed by Abacus.AI specifically for text generation tasks.
This model achieved an impressive average score of 80 on the leaderboard, reaching an important point for LLMs, and because it's open-source, you can definitely build some cool applications with that model.
Collaboration In Open Source AI
Collaboration is key to open source LLMs. When we make AI models open source, anyone can use, change and improve them. This means that developers from all over the world can work together to make AI better and more useful.
The Aya project is a great example of how open source LLMs can promote collaboration. It's a language model that can understand and follow instructions in 101 different languages, which is really amazing!

It was trained using a huge dataset called the Aya Dataset, which is the largest multilingual instruction fine-tuned dataset available. It's so big that it covers 114 languages and has 513 million examples.
I can think of many ways that Aya could be useful. For example, it could help people communicate across language barriers, or it could be used to create multilingual chatbots or virtual assistants.
You can try out the Aya model for yourself by visiting their playground and experimenting with it. Or you can use the Aya model to build your next multilingual app.
Join Newsletter
Don't miss articles like this – join our monthly newsletter!
Open Source Models Beyond NLP
Well, we've touched on some pretty impressive Language Models, haven't we? But you know what? There's a whole lot more to AI than just language. We're talking about vision, we're talking about audio—there's a whole world of models out there doing some seriously cool stuff.
They can understand speech, they can identify objects in images, and they can even handle different types of data all at once. Let's take a closer look at some of these game-changers:
Audio:
Whisper
Let's start with Whisper. Whisper is an incredible speech recognition model developed by OpenAI. Trained on a massive dataset, 680,000hrs to be exact, it's like having a super-smart assistant for understanding speech. The best part? It's open-source, meaning anyone can use its magic.
I recently built a tool using Whisper. It's pretty neat, actually. This tool does real-time sentiment analysis of speech, so you can understand the emotions behind the words.
You can try out the tool here, and learn more about it in this blog.
Oh, and speaking of awesome, there's a faster version called Distil-Whisper. Proposed in the paper "Robust Knowledge Distillation via Large-Scale Pseudo Labelling," Distil-Whisper is a distilled version of the Whisper model that's six times faster, 49% smaller, and performs within 1% Word Error Rate (WER) of Whisper on out-of-distribution evaluation sets.
It's designed to replace Whisper in English speech recognition tasks, offering faster inference without sacrificing accuracy. Plus, it's robust to noise and hallucinations, making it a reliable option for various applications. It's even licensed for commercial applications.
You can try them out in this space to compare them:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.0.2/gradio.js"></script>
<gradio-app src="https://devilent2-whisper-vs-distil-whisper-zero.hf.space"></gradio-app>
ReazonSpeech-Nemo-v2
Next is ReazonSpeech-Nemo-v2 model from Reazon Human Interaction Laboratory. ReazonSpeech-Nemo-v2 is a powerful speech recognition model tailored for Japanese audio.
Trained on the ReazonSpeech v2.0 corpus, it excels at processing long-form Japanese audio clips. With an enhanced Conformer architecture and 619 million parameters, this model offers efficient speech recognition.
The encoder uses Longformer attention, capturing Japanese speech nuances effectively, meanwhile, the decoder features a vocabulary space of 3000 tokens.
Computer Vision:
Vision-perciver Conv
vision-perceiver Conv is the first on our list, a state-of-the-art image classification model developed by Deepmind. Trained on the extensive ImageNet dataset, this model is designed to effortlessly classify images across various categories.
It is based on the groundbreaking Perceiver IO architecture, as described in the paper "Perceiver IO: A General Architecture for Structured Inputs & Outputs." This architecture enables it to handle structured inputs with remarkable efficiency and accuracy.
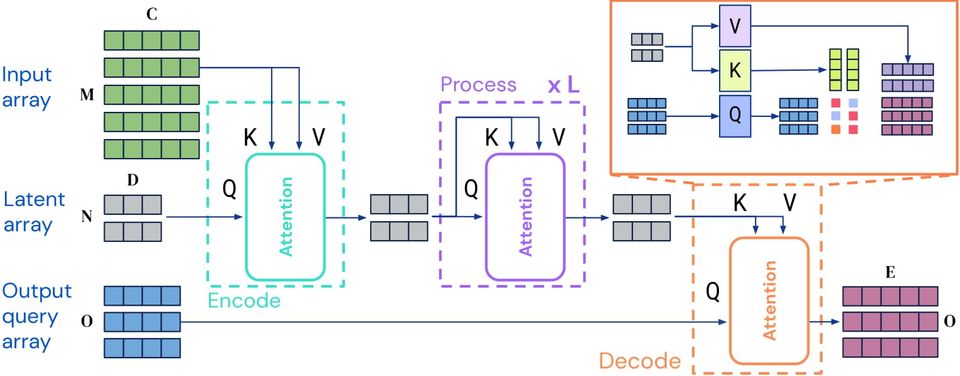
This model excels in image classification tasks but can also be fine-tuned for video tasks if needed. Keep in mind that there's also a multi-modal version of this model.
Want to try it out? Head over to this Hugging Face space to have a glance of its potential
Yolov8
Now Yolov8, developed by Ultralytics, stands out in object detection and image segmentation. It builds on the groundbreaking work of YOLO (You Only Look Once), as introduced in the paper "You Only Look Once: Unified, Real-Time Object Detection."
With YOLOv8, Ultralytics has taken that innovation further, revolutionizing real-time object detection and image segmentation. It's fast, accurate, and easy to use, seamlessly handling various tasks like object detection, tracking, segmentation, classification, and pose estimation.

You can also explore other open-source computer vision models, like those discussed in Merve Nolan's talk on the Open Source Computer Vision ecosystem.
Multimodal Large Lange Models (MLLM)
Multimodal models are advanced AI systems that can handle different types of data—text, images, audio, and video—all at once.
I won't go into the details how these models work or their complex architectures. Instead, I'll focus on showcasing some of the impressive multimodal models out there:
SeamlessM4T
SeamlessM4T is a pretty impressive multimodal model - honestly, I can't name many others like it before. It’s a new model, developed by Meta, that can handle translation across multiple languages and modalities.
What sets SeamlessM4T apart is its versatility. It’s an all-in-one model that can perform speech-to-text, speech-to-speech, text-to-speech, and text-to-text translations for up to 100 different languages. This comprehensive capability could really push multilingual AI forward.
You can find a video demonstrating SeamlessM4T here.
SeamlessM4T uses the Multitask UnitY model architecture, this lets it directly generate translations between speech, text, and speech-to-text automatically. For example, it can take speech input in Spanish and output text or speech in English.
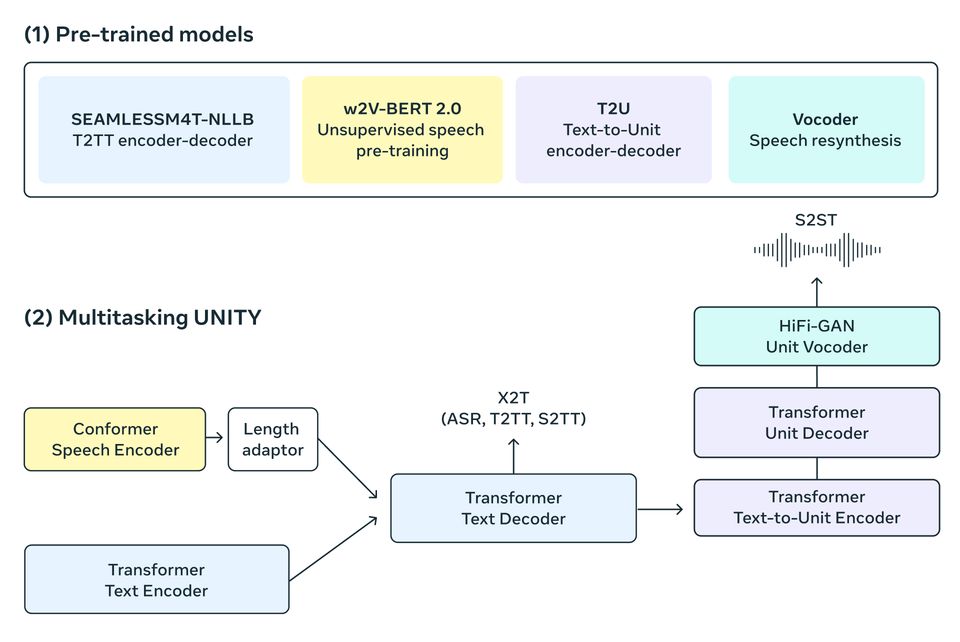
It builds on work by Meta in recent years toward creating universal translation systems. They previously released the "No Language Left Behind(NLLB)” text translation model covering 200 languages, and showed off a speech-to-speech translator for Hokkien.
I'm sure many of you, like me, already have ideas for building cool things with Seamless. But more on that in the next article!
ImageBind
ImageBind is another new model from Meta that's good at working with different data types like images, audio, text and motion data.
One thing cool about ImageBind is it makes one shared space to represent all those data types. This lets it find connections between the different types, or "modalities" as explained in the paper “ImageBind: One Embedding Space To Bind Them All”.
Before, AI embedding models needed huge labeled datasets to understand relationships across modalities. But ImageBind can link modalities without as much labeled data. By finding new connections between modalities, the model opens possibilities for things like retrieval information, classification, and using outputs from other models.
It's quite something! You can explore a demo of it here.
4M-21
The 4M framework is designed to train any-to-any foundation models by using tokenization and masking, enabling it to scale across numerous modalities. Models built with 4M excel at various vision tasks, adapt well to new tasks and modalities, and serve as versatile and steerable multimodal generative models. This concept was introduced in the paper "4M: Massively Multimodal Masked Modeling."
One example is the 4M-21 model, which stands out for its impressive capabilities across a wide array of vision and language use cases. By converting different modalities into sequences of tokens, a unified transformer encoder-decoder can be trained on text, images, geometric data, semantic data, and neural network feature maps. The training process involves mapping one random subset of tokens to another.
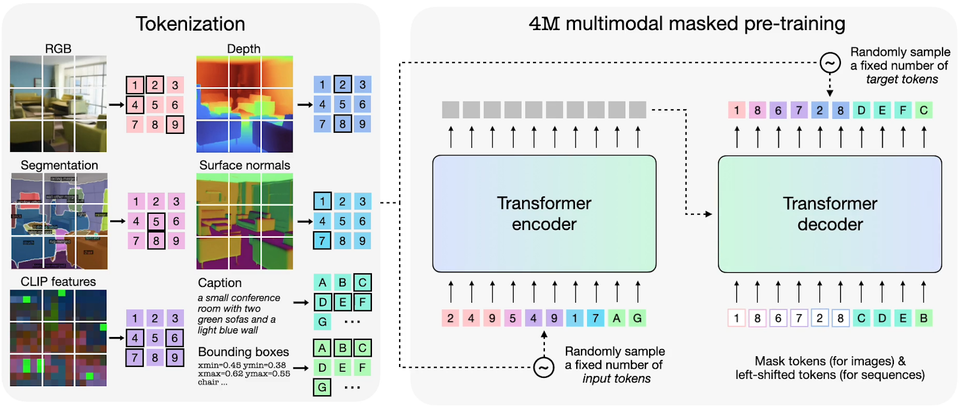
You can try it out in this space:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.36.1/gradio.js" ></script>
<gradio-app src="https://epfl-vilab-4m.hf.space"></gradio-app>
Benefits For Using Open Source LLMs
Well, by now I think you have an idea on why you should use open source models, maybe you've even switched to open source and become one of us 'open source lovers.' There are several benefits to using open source models aside from cost savings, let's take a look at some of them.
Transparency
One of the primary advantages of open source LLMs is their transparency. You'll have access to the model's architecture, training data, and mechanism for training and inference. This transparency allows for scrutiny, customization, and ensures ethical and legal compliance. With open source LLMs, you can inspect the code, understand how it works, and make changes to suit your specific needs. Additionally, optimizing an open-source LLM can lead to reduced latency and improved performance.
Data Privacy
Open-source LLMs offer a significant advantage when it comes to data security. Unlike proprietary models, open-source LLMs allow companies to maintain full control over their data, reducing the risk of data leaks or unauthorized access. This is particularly important for organizations that handle sensitive information, such as financial institutions, healthcare providers, and government agencies.
AI Footprint
AI models can have a significant environmental impact. Large language models (LLMs) often use a lot of energy and resources for training and operation. While most proprietary LLMs don't share info on their resource usage or environmental footprint, open-source LLMs do! This transparency can lead to new ways to reduce AI's environmental impact.
If you're interested in learning more about AI footprint and how to reduce it, check out this paper: "Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models.
How To Choose The Right Open Source LLM
Alright, that's quite a bit you've learned up to this point. But there's still more to explore. When picking a language model for an AI project, first decide what tasks you want it to do. Be specific. Will it analyze text? Images? Something else? Get very clear on what you want the model for.
Once you know the exact tasks, then you can focus on choosing the right model. You'll want to think about things like cost, accuracy, and performance.
Cost
Cost is a big factor. While open-source models are free, you still need to consider the computing costs for running them. Larger and more complex models require more data, processing power, infrastructure, and maintenance, which can add up. A huge model handling complex tasks might become expensive to host and train. Choose a model that fits your project goals without going overboard.
Accuracy
When evaluating models, accuracy is key. Check how well different open-source models handle the exact tasks you need for your project. Some models are designed for certain topics, while others can be improved with fine-tuning methods. The main thing is to test accuracy on your specific use case prompts.
Run experiments by giving models your real project questions and assess the answers to see if responses match what you expect.
Performance
You can check how well they handle large amounts of text data. Performance involves things like speed, scalability, and efficient use of memory and resources. Test models using your project's data, see how quickly they process inputs and generate coherent responses.
Screen for efficient data handling capabilities, a model that slows down or gets tripped up won't work well. Focus on ones that reliably process high volumes fast.
Bias
Evaluating bias is important for language models. Check their past testing and evaluations to see if they have biased or misleading outputs.
Good models are thoroughly evaluated or tested on many sample prompts, so their patterns are well understood by developers. You can test for bias yourself too using tools like Giskard.
Hands On State-Of-The-Art Open Source LLM: Gemma
Model Overview
So the model we chose here is Gemma 2, an open source language model recently released by Google Deepmind
Gemma comes in two main sizes - Gemma 9B and the larger Gemma 27B, each size has a pre-trained base version, as well as an instruction-tuned variant.
Google also released a Responsible Generative AI Toolkit that provides guidance and tools for safer applications using Gemma.
Gemma builds on the advanced proprietary work (Gemini) at Google. But now developers like you and me have open access to leverage these state-of-the-art natural language capabilities in their own projects.
Building With Gemma
We'll build a basic chatbot that you can interact with, using Gemma for the language model, for the interface we can use Gradio (or Streamlit if you prefer), finally we'll deploy it through Hugging Face space. This will be a good test run to see how Gemma handles a chatbot application. We can get it up and running quickly with just a few lines of code, then chat with it and evaluate the responses.
Alright, first thing first you must have all the necessary libraries installed. Install the latest version of Gradio and Hugging Face's Transformers, and note we are using colab notebook:
!pip install gradio~=4.19.1
!pip install transformers==4.27.0after that we import the libraries we need:
import gradio as gr
from huggingface_hub import InferenceClient
import randomInferenceClient allows interaction with the Gemma model, gradio helps in building the user interface, and random.
Next we create a client to connect to Gemma:
client = InferenceClient("google/gemma-2-9b-it")This line creates a client to communicate with the Gemma model hosted on the Hugging Face model hub.
The next step will be to create two functions for the prompts and the generation
def format_prompt(message, history):
prompt = ""
if history:
for user_prompt, bot_response in history:
prompt += f"<start_of_turn>user{user_prompt}<end_of_turn>"
prompt += f"<start_of_turn>model{bot_response}"
prompt += f"<start_of_turn>user{message}<end_of_turn><start_of_turn>model"
return promptIn this block, we define a function called format_prompt, with that, we prepare the input for the Gemma model, and iterate through the conversation history, adding user inputs and model responses to the prompt
def generate(prompt, history, temperature=0.7, max_new_tokens=1024, top_p=0.90, repetition_penalty=0.9):
temperature = float(temperature)
if temperature < 1e-2:
temperature = 1e-2
top_p = float(top_p)
if not history:
history = []
rand_seed = random.randint(1, 1111111111111111)
generate_kwargs = dict(
temperature=temperature,
max_new_tokens=max_new_tokens,
top_p=top_p,
repetition_penalty=repetition_penalty,
do_sample=True,
seed=rand_seed,
)
formatted_prompt = format_prompt(prompt, history)
stream = client.text_generation(formatted_prompt, **generate_kwargs, stream=True, details=True, return_full_text=False)
output = ""
for response in stream:
output += response.token.text
yield output
history.append((prompt, output))
return outputThis function is responsible for generating responses using the Gemma model. What is that It takes several parameters, including prompt (the formatted input prompt), history, and various generation parameters and (if necessary) adjusts the temperature parameter to ensure it falls within a valid range.
Next is the chatbot interface:
mychatbot = gr.Chatbot(
avatar_images=["./user.png", "./botgm.png"],
bubble_full_width=False,
show_label=False,
show_copy_button=True,
likeable=True,
)
additional_inputs = [
# Additional input sliders for controlling generation parameters
]
iface = gr.ChatInterface(
fn=generate,
chatbot=mychatbot,
additional_inputs=additional_inputs,
retry_btn=None,
undo_btn=None,
)This code uses Gradio to create the chatbot interface. It sets up things like:
- Avatars for the user and bot
- Controls for sending messages
- Buttons to retry or undo messages
- Other customizations for how the chatbot looks and works
Next we create an HTML block to display the interface
with gr.Blocks() as demo:
gr.HTML("<center><h1>GEMMA CHATBOT</h1></center>")
iface.render()This HTML block will hold the chatbot interface we defined earlier. The title indicates it's a chatbot powered by Gemma.
And finally, we launch the Gradio app to let you interact with the chatbot:
demo.queue().launch(show_api=False)After launching the app, you can deploy it with Hugging Face Spaces. This lets anyone try the chatbot. You can check the docs to learn how to deploy properly, and also add bot and user images to the space for the best look.
Then your deployed chatbot could look like this:
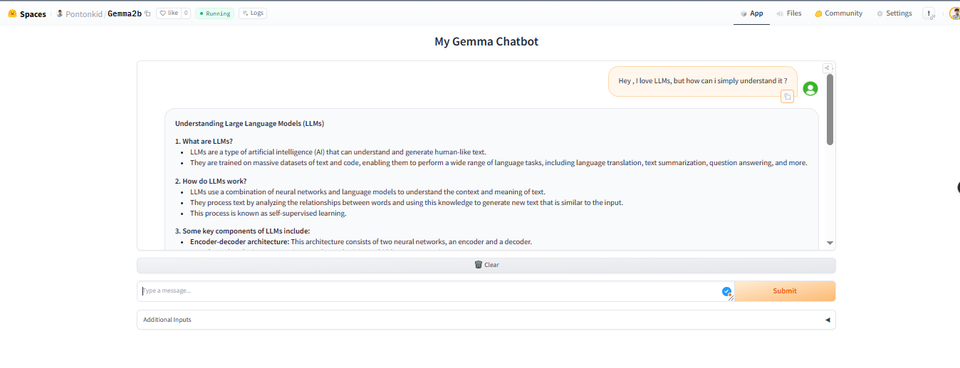
Voila! Well done, you have just built your own chatbot with Gemma.
Building this chatbot let you try out Gemma 2 hands-on, but you can also compare models in the Chatbot Arena.
The Chatbot Arena lets you chat with different open source models. See how Gemma stacks up against other options.
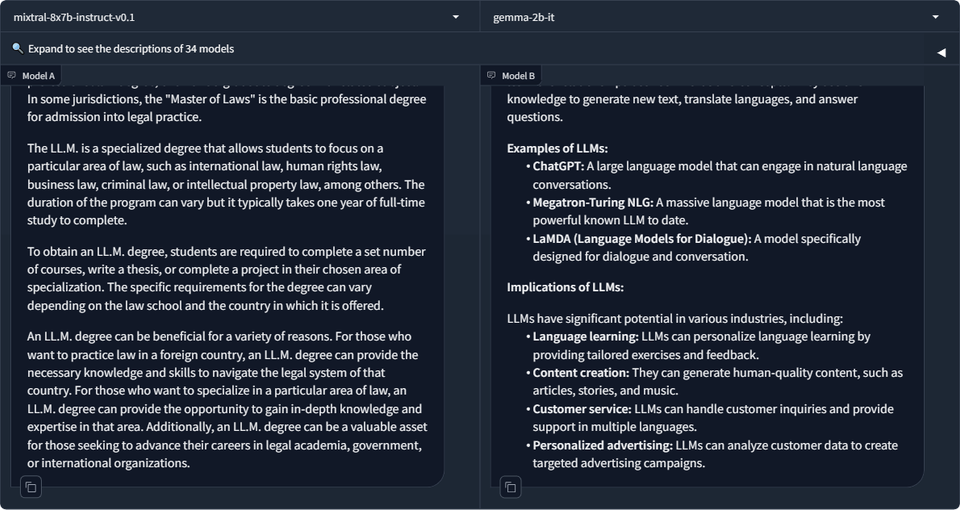
It's fun to chat and compare Gemma to other models yourself; this Arena makes it easy.
How To Deploy Open Source Large Language Models
There are many options available to deploy your Large Language Models (LLMs), including various frameworks and platforms. I won't overwhelm you with technical details; instead, I'll give you a quick rundown of your options, so you can get a sense of what's out there.
Hugging Face Inference Endpoints
Hugging Face Inference Endpoints provide a straightforward way to deploy models. They handle setting up servers on cloud platforms like AWS for you. All you need is a Hugging Face repository with your trained model.
Simply launch an endpoint attached to your repo with your desired cloud instance type and location. Endpoints manage the infrastructure dependencies seamlessly so you can focus on using your model.
Main benefits:
- Easy deployment - Set up production APIs in clicks without managing servers yourself.
- Cost efficient - Automatically scales down when not in use to reduce costs. Only pay for uptime.
- LLM optimization - Enables fast response times and high throughput.
OpenLLM
OpenLLM is a platform, developed by BentoML, that makes it easy to use large language models (LLMs) in real-world applications. It supports a wide range of open-source LLMs and allows you to run inference on any of them. You can deploy these models on the cloud or on your own premises, and use them to build powerful AI applications.
Key Features:
- State-of-the-art Language Models: Works with many open-source LLMs, including Llama 2, StableLM, Falcon, and more.
- APIs: Easily serve LLMs using a simple RESTful API or gRPC command.
- Building: Supports LangChain, BentoML, LlamaIndex, OpenAI endpoints, and Hugging Face, making it easy to create your own AI apps.
- Deployment: Automatically generates Docker images or deploys serverless endpoints with BentoCloud, which manages resources and scales efficiently.
Runpod
RunPod is a cloud-based platform that makes it easy to run large language models (LLMs) on servers with GPUs. This can be really helpful if you're working on projects that require a lot of computing power. With RunPod, you can quickly launch a GPU instance and scale inference on your models with serverless technology.
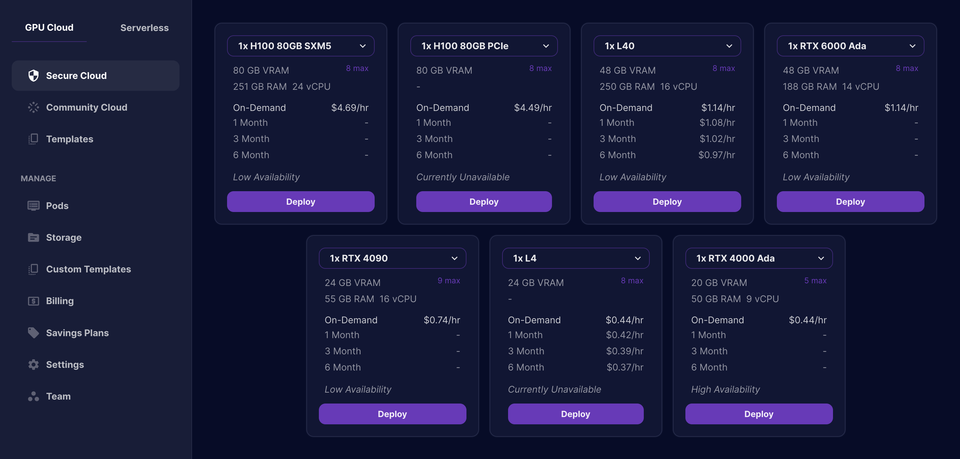
Key features :
- Develop, train, and scale AI models
- Launch a GPU instance in seconds
- Scale inference on your models with serverless
- Cost-effective GPU cloud platform built for production
Other cost-effective cloud servers with powerful enough GPUs include Lambda and CoreWeave. You can learn more about RunPod and its features by checking out their documentation.
Monitoring Large Language Models
Deploying your large lange model is only one part of the job , monitoring its performance and make sure it's running smoothly, is also as crucila.
Here are some of the best practices for monitoring LLMs:
Choose the right metrics: Select a mix human evaluation metrics that reflect the comprehensive capabilities and impacts of your LLM.
Set up effective alerting systems: Design alerting systems that are responsive and precise, with clear thresholds, monitoring frequencies, and escalation paths for each identified metric.
Ensure reliability and scalability: Monitor performance metrics, automate processes, and use cloud-based solutions for flexible scaling.
Run adversarial tests: Regularly challenge your LLM to identify and strengthen vulnerabilities using token manipulation, gradient-based, and jailbreak prompting attacks, and consider red-teaming techniques.
Data integrity and model input: Perform data quality checks, bias detection, and input validation while monitoring for anomalies and drift.
And you can use tools like Whylabs, Giskard, or Comet to help you streamline the process and ensure that your LLMs are performing well.
Conclusion
Whew, that was a journey! The open source approach is changing the game for AI development, and we've only scratched the surface of its potential. I believe projects like Aya will continue to emerge, and they'll only get more powerful.
It's an exciting time to be a part of this, and to learn more, I recommend checking out Yann LeCun's article on how an open source approach could shape AI